
Thinking Machines Lab
Founded Year
2024Stage
Seed VC | AliveTotal Raised
$2.01BValuation
$0000Last Raised
$2B | 3 mos agoAbout Thinking Machines Lab
Thinking Machines Lab develops artificial intelligence systems. The company develops AI tools that are customizable and can work with humans in domains such as science and programming. Thinking Machines Lab also focuses on AI safety and alignment to prevent misuse and contribute to the understanding of AI technologies. It was founded in 2024 and is based in San Francisco, California.
Loading...
Loading...
Research containing Thinking Machines Lab
Get data-driven expert analysis from the CB Insights Intelligence Unit.
CB Insights Intelligence Analysts have mentioned Thinking Machines Lab in 3 CB Insights research briefs, most recently on Aug 19, 2025.
Aug 19, 2025
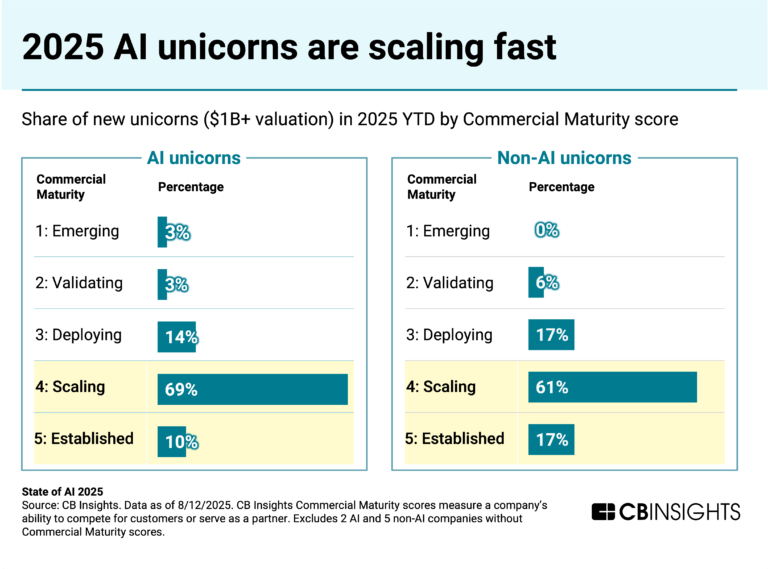
Are AI unicorns starting to move beyond hype?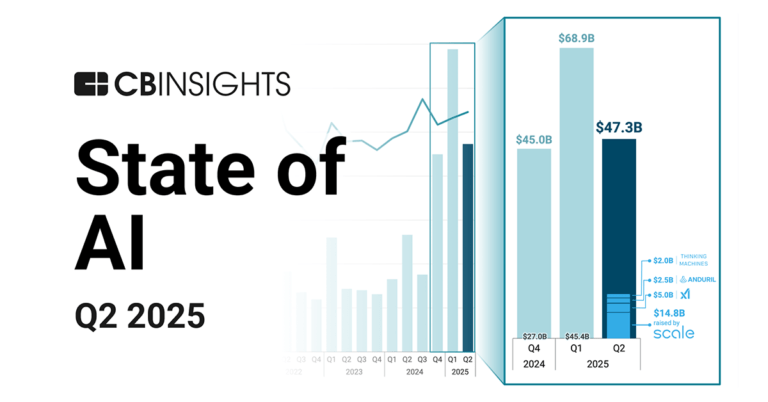
Jul 31, 2025 report
State of AI Q2’25 Report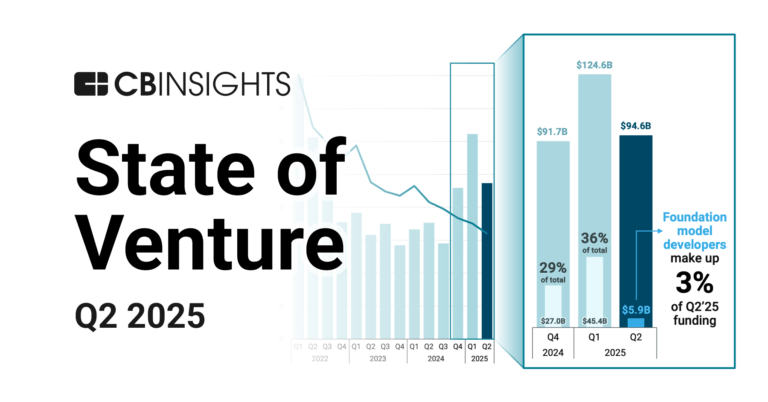
Jul 10, 2025 report
State of Venture Q2’25 ReportExpert Collections containing Thinking Machines Lab
Expert Collections are analyst-curated lists that highlight the companies you need to know in the most important technology spaces.
Thinking Machines Lab is included in 2 Expert Collections, including Artificial Intelligence.
Artificial Intelligence
10,402 items
Unicorns- Billion Dollar Startups
1,286 items
Latest Thinking Machines Lab News
Sep 14, 2025
The tech giant took Wall Street by surprise with an amazing performance driven by its AI computing capabilities. Sep 14, 2025 Next Week in The Sequence: The Sequence Knowledge: Our series about AI interpretability continues with an introduction to sparse autoencoders and some groundbreaking research from OpenAI in that area. The Sequence Opinion: Discusses the possibilities and challenges of building a transformer for robotics. The Sequence AI of the Week: Reviews Thinking Machines’ opening work on non-deterministic foundation models Subscribe Now to Not Miss Anything: TheSequence is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber. Subscribe 📝 Editorial: Oracle’s Quiet AI Decade, Loud Week Oracle just had the kind of AI week that forces a narrative rewrite. Beyond a historic market reaction, the company highlighted a step‑change in AI demand flowing into its contracted backlog and, per multiple reports, is locking in one of the largest multi‑year compute agreements in the industry—reportedly set to kick in mid‑decade. Whatever you thought Oracle was—a “legacy database vendor”—now looks more like an AI infrastructure company with a data‑centric moat. Why has Oracle been underestimated next to Microsoft, Google, Amazon, and Meta? Because it avoided the arms race at the model layer and built the unfashionable substrate instead: data, governance, and distribution. The strategy is pragmatic and, in hindsight, obvious—be the neutral fabric that makes other people’s models safe and useful where enterprise data already lives. This shows up in multicloud reality, not slides: Oracle Database services running natively inside other hyperscalers’ datacenters so LLMs and analytics can co‑locate with regulated data without cross‑cloud contortions. On raw compute, Oracle Cloud Infrastructure (OCI) has been shipping the right primitives for modern AI factories. Supercluster designs pair Blackwell‑class GPU systems (e.g., GB200 NVL72 pods) with high‑bandwidth fabrics, liquid cooling, NVLink for intra‑node communication, and RDMA networking across racks. The result is a platform built for the messy workloads that define the frontier—long‑context training, mixture‑of‑experts sharding, retrieval‑heavy inference, and agentic pipelines that spike bandwidth rather than only FLOPs. The quiet killer feature is the data plane. Oracle Database 23ai brings vector search into the core engine alongside JSON‑relational duality, graph queries, and GoldenGate replication—so semantic and relational queries run side‑by‑side with the same governance, HA/DR, and recovery you already trust. In practical terms, it collapses today’s brittle pattern—export to a separate vector store and hope your policies follow—into a single transactional system. It’s the difference between a demoable RAG stack and a production‑auditable one. Distribution is where this advantage compounds. Dedicated Region, Cloud@Customer, Alloy (partner‑operated clouds), and EU Sovereign Cloud let the same AI stack land in bank vaults, hospitals, and ministries—where the data must live—while bursting to GPU superclusters when scale is needed. Combine that with a first‑class multicloud database footprint and enterprises get a realistic path to adopt training, finetuning, and high‑throughput inference without tearing up their compliance posture. For technical teams, the implications are concrete. Model builders gain another deep pool of cutting‑edge GPUs with modern fabric for massive context and agentic workflows. Data teams can bring LLMs to the data via 23ai rather than spraying sensitive records across third‑party stores. Architects keep true multicloud optionality—databases co‑located where the business runs; models wherever they run best. Oracle has been underestimated precisely because it invested in the unglamorous layers. As AI moves from demos to operations, those layers are where the profit pools—and the production risks—actually live. 🔎 AI Research AI Lab: Thinking Machines Lab Summary: This blog post identifies that the usual suspicion — “floating-point + concurrency” — doesn’t fully explain why large language model inference endpoints yield non-identical outputs even with temperature 0, and points out that the real culprit is batch-dependence (i.e. kernels not being “batch invariant”) leading to varying reduction orders depending on how many simultaneous requests or tokens are being processed. They show how to build batch-invariant kernels (for operations like RMSNorm, matrix multiplication, attention) so that inference becomes truly reproducible, and demonstrate this by implementing them in vLLM: with the new kernels, 1000 identical zero-temperature runs produce bitwise identical completions. AI Lab: Meta Superintelligence Labs, UC Berkeley Summary: This paper introduces Language Self-Play (LSP), a reinforcement learning method where a single LLM improves by acting as both Challenger (query generator) and Solver (responder), removing reliance on external datasets. Experiments with Llama-3.2-3B show that LSP matches or surpasses data-driven RL baselines, demonstrating the feasibility of perpetual self-improvement without additional training data. AI Lab: Google DeepMind, Google Research Summary: This work introduces SimpleQA Verified, a rigorously filtered 1,000-prompt benchmark that addresses noise, redundancy, and biases in OpenAI’s SimpleQA dataset. It provides a more reliable tool to measure LLM factuality, with Gemini 2.5 Pro achieving state-of-the-art performance, outperforming even GPT-5. AI Lab: MiniMax, HKUST, University of Waterloo Summary: The paper presents WebExplorer, a framework that generates challenging web navigation QA pairs using model-based exploration and long-to-short iterative query evolution. Training the 8B-parameter WebExplorer model with this data enables state-of-the-art long-horizon reasoning, outperforming much larger models like WebSailor-72B across benchmarks such as BrowseComp and WebWalkerQA. AI Lab: Stanford University (Departments of Genetics, Biomedical Data Science, Biology, Computer Science) Summary: Paper2Agent is a system that converts research papers into interactive AI agents by building Model Context Protocol (MCP) servers that expose methods, datasets, and workflows as callable tools. Case studies on AlphaGenome, TISSUE, and Scanpy show that these paper-agents can faithfully reproduce original results and support novel analyses, creating a new paradigm for dynamic scientific knowledge dissemination. AI Lab: Google DeepMind, Google Research, Harvard University, MIT, McGill, Caltech Summary: This paper presents a system that combines large language models with tree search to automatically generate and refine scientific software for scorable tasks—problems where performance can be measured against a quality metric. Across benchmarks in genomics, epidemiology, geospatial analysis, neuroscience, time series forecasting, and numerical integration, the system produced expert-level and often state-of-the-art solutions, including 40 new methods for single-cell analysis and 14 models surpassing the CDC’s COVID-19 forecasting ensemble 🤖 AI Tech Releases
Thinking Machines Lab Frequently Asked Questions (FAQ)
When was Thinking Machines Lab founded?
Thinking Machines Lab was founded in 2024.
Where is Thinking Machines Lab's headquarters?
Thinking Machines Lab's headquarters is located at San Francisco.
What is Thinking Machines Lab's latest funding round?
Thinking Machines Lab's latest funding round is Seed VC.
How much did Thinking Machines Lab raise?
Thinking Machines Lab raised a total of $2.01B.
Who are the investors of Thinking Machines Lab?
Investors of Thinking Machines Lab include Andreessen Horowitz, NVIDIA, Jane Street Group, Accel, Advanced Micro Devices and 7 more.
Loading...
Loading...